
Cost and Usage Report(CUR)を使用してAmazon Athenaで継続的な期間を分析する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWSでは、AWSサービスの利用明細などが記載された Cost and Usage Report(CUR)というレポートを取得できます。
弊社が提供しているAWS総合支援サービスである クラスメソッドメンバーズ でもAWSのレガシーCURの仕様に則ったCURを出力可能です。
メンバーズのCURでは、本サービスにご加入いただくことで適用されるAWS利用費の割引を含めた利用明細を確認できます。
今回はこのCUR(CSVフォーマット)を蓄積していき、年月を跨いだ継続的な期間の分析をAthenaで行う方法を2パターン紹介します。
- Glueを使った方法
- AthenaのPartition Projectionを使った方法
継続的な期間の分析は必要なく単発で分析を行いたい場合は、下記の武田のエントリを参考にしてみてください。
前提
Athenaで分析するCURの出力設定を下記とします。
| フォーマット | S3バケット | S3パスプレフィックス | エクスポート名 |
|---|---|---|---|
| CSV | cm-cur-123456789012 | mcur/account_id=123456789012 | account-cur-csv |
S3バケットは メンバーズポータルユーザーガイド 記載のCloudFormationから作成します。
S3バケットとS3パスプレフィックスの 123456789012 部分は、バケットを所有するご自身のアカウントのAWSアカウントIDに読み替えてください。
メンバーズのCUR(CSVフォーマット)は、お客様が指定したS3バケットの下記のようなパスに概ね一日2回出力されます。
cm-cur-123456789012/
└ mcur/
└ account_id=123456789012/
└ account-cur-csv/
├ 20240901-20241001/
├ 20241001-20241101/
└ 20241101-20241201/
├ account-cur-csv-Manifest.json
├ 535c4219-2e94-48c0-8284-ce7bd771b7bc/
├ 7166ce8e-26f4-4001-9406-a2cbfe6b8aed/
└ 77f6f7d-29b2-4bc4-9369-302a5204d864/
├ account-cur-csv-Manifest.json
├ account-cur-csv-1.csv.gz
├ account-cur-csv-2.csv.gz
├ account-cur-csv-3.csv.gz
├ account-cur-csv-4.csv.gz
└ account-cur-csv-5.csv.gz
このCURは上書きされないバージョン形式として出力され、出力毎に 77f6f7d-29b2-4bc4-9369-302a5204d864 のような異なるUUIDのパス配下にファイルが出力されていきます(このUUIDをassemblyIdと言います)。
どの出力が最新のものかは 20241101-20241101/ のようなパス直下の account-cur-csv-Manifest.json ファイルにassemblyIdの項目として記載されています。
最新のCURをAthenaで分析するために、CURが出力されると別のバケットに上書きコピーを行い、最新のデータを参照できるような環境を構築していきます。
1. Glueを使った方法
構築するアーキテクチャ図を示します。
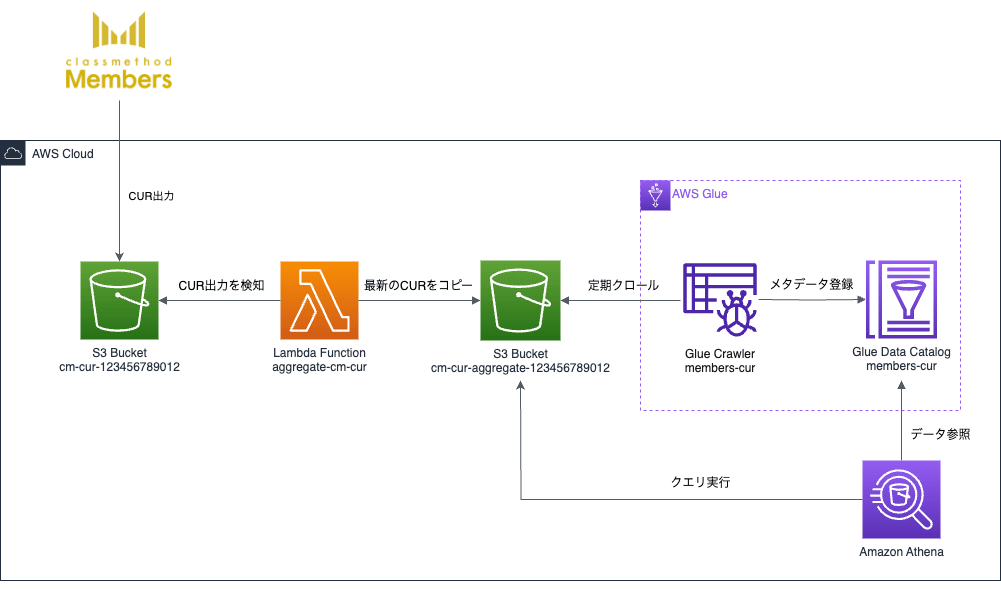
各リソースの説明は次の通りです。
| リソース名 | 説明 |
|---|---|
| S3 Bucket cm-cur-123456789012 |
メンバーズのCURが出力されるS3バケット |
| Lambda Function aggregate-cm-cur |
cm-cur-123456789012バケットから最新のCURをcm-cur-aggregate-123456789012バケットにコピーするLambda関数 |
| S3 Bucket cm-cur-aggregate-123456789012 |
最新のCURがコピーされるS3バケット |
| Glue Crawler members-cur |
cm-cur-aggregate-123456789012バケットを定期的にクロールするCrawler |
| Glue Data Catalog members-cur |
Crawlerにクロールされたメタデータが保存されるデータカタログ |
| Amazon Athena | CURを分析するAthena |
この環境をAWS CLIで構築していきます。
CURコピー先S3バケットの作成
出力された最新のCURをコピーする先のS3バケットを作成します。
aws s3api create-bucket \
--bucket cm-cur-aggregate-123456789012 \
--region ap-northeast-1 \
--create-bucket-configuration LocationConstraint=ap-northeast-1
Lambda関数の作成
Lambda用のIAMロールを作成します。
aws iam create-role \
--role-name aggregate-cm-cur-role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
作成したIAMロールに、CloudWatchログの保存とS3バケットへの読み書き用のインラインポリシーを追加します。
aws iam put-role-policy \
--role-name aggregate-cm-cur-role \
--policy-name aggregate-cm-cur-policy \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:123456789012:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:123456789012:log-group:/aws/lambda/aggregate-cm-cur:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::cm-cur-123456789012",
"arn:aws:s3:::cm-cur-123456789012/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::cm-cur-aggregate-123456789012",
"arn:aws:s3:::cm-cur-aggregate-123456789012/*"
]
}
]
}'
Lambda関数で実行するPythonのコードを保存します。
Pythonのバージョンは 3.13 を想定しています。
コードは下記の通りです。
import boto3
import re
import os
import urllib.parse
import concurrent.futures
def list_s3_objects(s3_client, bucket, prefix):
paginator = s3_client.get_paginator('list_objects_v2')
for page in paginator.paginate(Bucket=bucket, Prefix=prefix):
if page['KeyCount'] == 0:
break
yield from page.get('Contents', [])
def copy_object(s3_client, source_bucket, dest_bucket, source_key, dest_key):
try:
s3_client.copy_object(
Bucket=dest_bucket,
CopySource={
'Bucket': source_bucket,
'Key': source_key
},
Key=dest_key
)
return f"Copied {source_key} to {dest_key}"
except Exception as e:
return f"Error copying {source_key}: {str(e)}"
def lambda_handler(event, context):
# 環境から設定を取得
s3_prefix = os.environ.get('s3_prefix')
export_name = os.environ.get('export_name')
source_bucket = os.environ.get('source_bucket')
dest_bucket = os.environ.get('dest_bucket')
# S3クライアントの初期化
s3_client = boto3.client('s3')
# イベントからバケット名とオブジェクトキーを取得
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# キーをデコード
decoded_key = urllib.parse.unquote(key)
# 対象のパターンに一致するか確認
pattern = fr'^{s3_prefix}([^/]+)/{export_name}/(\d{{8}}-\d{{8}})/.*/{export_name}-Manifest\.json$'
match = re.match(pattern, decoded_key)
if not match:
print(f"Skipping file: {key} - Does not match the required pattern")
return {
'statusCode': 200,
'body': 'Not the target file, skipping processing'
}
# パターンからaccount_idと日付範囲を抽出
account_id = match.group(1)
date_range = match.group(2)
try:
# ソースディレクトリを取得(Manifestファイルがあるディレクトリ)
source_dir = os.path.dirname(decoded_key)
# 並行コピー処理
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
# コピージョブの準備
copy_jobs = []
for obj in list_s3_objects(s3_client, source_bucket, source_dir):
source_key = obj['Key']
# 新しいコピー先キーを生成
dest_key = (
f'{s3_prefix}{account_id}/export_name={export_name}/date={date_range[:6]}/'
f'{os.path.basename(source_key)}'
)
# コピージョブを追加
copy_jobs.append(
executor.submit(
copy_object,
s3_client,
source_bucket,
dest_bucket,
source_key,
dest_key
)
)
# 結果の処理
for future in concurrent.futures.as_completed(copy_jobs):
print(future.result())
return {
'statusCode': 200,
'body': 'Successfully cpied files'
}
except Exception as e:
print(f"Error processing files: {str(e)}")
return {
'statusCode': 500,
'body': f'Error: {str(e)}'
}
上記Pythonのコードを lambda_function.py として保存し、function.zip に圧縮します。
zip function.zip lambda_function.py
Lambda関数を作成します。
memory-size ephemeral-storage timeout の設定は、ご自身のCURの出力サイズにより適宜調整してください。
aws lambda create-function \
--function-name aggregate-cm-cur \
--runtime python3.13 \
--handler lambda_function.lambda_handler \
--role arn:aws:iam::123456789012:role/aggregate-cm-cur-role \
--architectures x86_64 \
--memory-size 512 \
--ephemeral-storage Size=512 \
--timeout 300 \
--environment "Variables={
dest_bucket=cm-cur-aggregate-123456789012,
export_name=account-cur-csv,
s3_prefix=mcur/account_id=,
source_bucket=cm-cur-123456789012
}" \
--zip-file fileb://function.zip
S3通知からLambda関数を呼び出すための権限を付与します。
aws lambda add-permission \
--function-name aggregate-cm-cur \
--statement-id S3InvokeFunction \
--action lambda:InvokeFunction \
--principal s3.amazonaws.com \
--source-arn arn:aws:s3:::cm-cur-123456789012 \
--source-account 123456789012
S3通知をLambda関数のトリガーとして設定します。
aws s3api put-bucket-notification-configuration \
--bucket cm-cur-123456789012 \
--notification-configuration '{
"LambdaFunctionConfigurations": [{
"LambdaFunctionArn": "arn:aws:lambda:ap-northeast-1:123456789012:function:aggregate-cm-cur",
"Events": ["s3:ObjectCreated:*"],
"Filter": {
"Key": {
"FilterRules": [{
"Name": "suffix",
"Value": "account-cur-csv-Manifest.json"
}]
}
}
}]
}'
以上でLambdaの設定は完了です。
cm-cur-123456789012バケットにCURが出力されると、cm-cur-aggregate-123456789012バケットに最新のCURがコピーされます。
コピー先は mcur/account_id=123456789012/export_name=account-cur-csv/date=202412/ のようなパスになります。
Glueクローラの作成
AWS Glue Crawlerを利用して、cm-cur-aggregate-123456789012バケットにコピーされたCURをAthenaで分析するために必要なリソースを作成します。
Glueのデータベースを作成します。
aws glue create-database \
--database-input '{
"Name": "members-cur",
"Description": "Database for Members CUR"
}'
Glueクローラ用のIAMロールを作成します。
aws iam create-role \
--role-name AWSGlueServiceRole-CmCurAggregate \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
IAMロールにAWS管理ポリシーをアタッチします。
aws iam attach-role-policy \
--role-name AWSGlueServiceRole-CmCurAggregate \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
IAMロールにS3バケット読み書き用のインラインポリシーを追加します。
aws iam put-role-policy \
--role-name AWSGlueServiceRole-CmCurAggregate \
--policy-name S3Access \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::cm-cur-aggregate-123456789012/mcur/*"
]
}
]
}'
Glueクローラを作成します。
schedule は毎日0時に実行されるようにしています。
一時的な利用であれば schedule の指定を削除してオンデマンド実行にしてください。
aws glue create-crawler \
--name members-cur \
--role "AWSGlueServiceRole-CmCurAggregate" \
--targets '{
"S3Targets": [
{
"Path": "s3://cm-cur-aggregate-123456789012/mcur/",
"Exclusions": ["**.json"]
}
]
}' \
--database-name members-cur \
--schedule "cron(0 0 * * ? *)" \
--recrawl-policy "RecrawlBehavior=CRAWL_NEW_FOLDERS_ONLY"
以上で全ての設定は完了です。
CURが出力されるとcm-cur-aggregate-123456789012バケットに最新のCURのみがコピーされ、クローラの定期実行により最新のメタデータが登録されます。
2. AthenaのPartition Projectionを使った方法
AthenaのPartition Projectionを使用することで、Glueのクローラを使用することなくAthenaでの分析が可能です。
Glueの環境を構築する必要がない分、設定としてはこちらの方がシンプルになります。
Glueを使った方法と、AthenaのPartition Projectionを使った方法との比較は後述します。
Partition Projectionについては、下記のエントリ等を参照してください。
構築するアーキテクチャ図を示します。
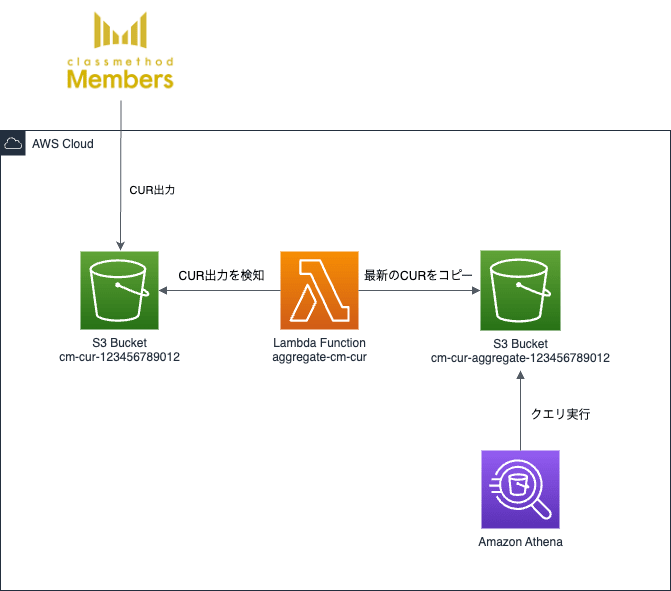
「1. Glueを使った方法」の「Lambda関数の作成」までの設定は同様です。
それ以降の設定を記載します。
Athenaテーブルの作成
まずはテーブルを作成するためのデータベースを作成します。
Athena上で下記クエリを実行してください。
CREATE DATABASE `members-cur`;
次に、作成したデータベースに下記DDLでテーブルを作成します。
CREATE EXTERNAL TABLE `mcur` (
`account_id` string,
`identity/lineitemid` string,
`identity/timeinterval` string,
`bill/invoiceid` string,
`bill/billingentity` string,
`bill/billtype` string,
`bill/payeraccountid` string,
`bill/billingperiodstartdate` string,
`bill/billingperiodenddate` string,
`bill/invoicingentity` string,
`lineitem/usageaccountid` string,
`lineitem/lineitemtype` string,
`lineitem/usagestartdate` string,
`lineitem/usageenddate` string,
`lineitem/productcode` string,
`lineitem/usagetype` string,
`lineitem/operation` string,
`lineitem/availabilityzone` string,
`lineitem/resourceid` string,
`lineitem/usageamount` double,
`lineitem/normalizationfactor` double,
`lineitem/normalizedusageamount` double,
`lineitem/currencycode` string,
`lineitem/unblendedrate` double,
`lineitem/unblendedcost` double,
`lineitem/lineitemdescription` string,
`lineitem/taxtype` string,
`lineitem/legalentity` string,
`product/productname` string,
`product/acceleratorsize` string,
`product/acceleratortype` string,
`product/accesstype` string,
`product/activitytype` string,
`product/addonfeature` string,
`product/alarmtype` string,
`product/apitype` string,
`product/attachmenttype` string,
`product/availability` string,
`product/availabilityzone` string,
`product/bitrate` string,
`product/brokerengine` string,
`product/bundle` string,
`product/cacheengine` string,
`product/cachememorysizegb` string,
`product/callingtype` string,
`product/capacitystatus` string,
`product/category` string,
`product/clientlocation` string,
`product/clockspeed` string,
`product/cloudsearchversion` string,
`product/codec` string,
`product/computefamily` string,
`product/computetype` string,
`product/concurrencyscalingfreeusage` string,
`product/contenttype` string,
`product/country` string,
`product/countsagainstquota` string,
`product/cputype` string,
`product/currentgeneration` string,
`product/data` string,
`product/datatransfer` string,
`product/datatransferquota` string,
`product/databaseedition` string,
`product/databaseengine` string,
`product/datatransferout` string,
`product/dedicatedebsthroughput` string,
`product/deploymentlocation` string,
`product/deploymentoption` string,
`product/describes` string,
`product/description` string,
`product/device` string,
`product/devicetype` string,
`product/directconnectlocation` string,
`product/directorysize` string,
`product/directorytype` string,
`product/directorytypedescription` string,
`product/dominantnondominant` string,
`product/durability` string,
`product/ebsoptimized` string,
`product/ecu` string,
`product/edition` string,
`product/elasticgraphicstype` string,
`product/endpoint` string,
`product/endpointtype` string,
`product/engine` string,
`product/enginecode` string,
`product/enhancednetworkingsupport` string,
`product/enhancednetworkingsupported` string,
`product/entitytype` string,
`product/eventtype` string,
`product/executionfrequency` string,
`product/executionlocation` string,
`product/feecode` string,
`product/feedescription` string,
`product/filesystemtype` string,
`product/framerate` string,
`product/freeoverage` string,
`product/freequerytypes` string,
`product/freetier` string,
`product/freetrial` string,
`product/freeusageincluded` string,
`product/frequencymode` string,
`product/fromlocation` string,
`product/fromlocationtype` string,
`product/georegioncode` string,
`product/gets` string,
`product/gpu` string,
`product/gpumemory` string,
`product/graphqloperation` string,
`product/group` string,
`product/groupdescription` string,
`product/highavailability` string,
`product/indexingsource` string,
`product/ingesttype` string,
`product/input` string,
`product/inputmode` string,
`product/instance` string,
`product/instancecapacity10xlarge` string,
`product/instancecapacity12xlarge` string,
`product/instancecapacity24xlarge` string,
`product/instancecapacity2xlarge` string,
`product/instancecapacity4xlarge` string,
`product/instancecapacity8xlarge` string,
`product/instancecapacitylarge` string,
`product/instancecapacityxlarge` string,
`product/instancefamily` string,
`product/instancefunction` string,
`product/instancetype` string,
`product/instancetypefamily` string,
`product/instances` string,
`product/instancesku` string,
`product/intelavx2available` string,
`product/intelavxavailable` string,
`product/intelturboavailable` string,
`product/io` string,
`product/license` string,
`product/licensemodel` string,
`product/licensetype` string,
`product/linetype` string,
`product/location` string,
`product/locationtype` string,
`product/logssource` string,
`product/logstype` string,
`product/machinelearningprocess` string,
`product/mailboxstorage` string,
`product/maxiopsburstperformance` string,
`product/maxiopsvolume` string,
`product/maxthroughputvolume` string,
`product/maxvolumesize` string,
`product/maximumcapacity` string,
`product/maximumextendedstorage` string,
`product/maximumstoragevolume` string,
`product/memory` string,
`product/memorygib` string,
`product/memorytype` string,
`product/messagedeliveryfrequency` string,
`product/messagedeliveryorder` string,
`product/meteringtype` string,
`product/minvolumesize` string,
`product/minimumstoragevolume` string,
`product/networkperformance` string,
`product/newcode` string,
`product/normalizationsizefactor` string,
`product/offer` string,
`product/operatingsystem` string,
`product/operation` string,
`product/operationtype` string,
`product/opsitems` string,
`product/origin` string,
`product/oslicensemodel` string,
`product/output` string,
`product/outputmode` string,
`product/overagetype` string,
`product/parametertype` string,
`product/physicalcores` string,
`product/physicalcpu` string,
`product/physicalgpu` string,
`product/physicalprocessor` string,
`product/pipeline` string,
`product/portspeed` string,
`product/preinstalledsw` string,
`product/processorarchitecture` string,
`product/processorfeatures` string,
`product/productfamily` string,
`product/protocol` string,
`product/provisioned` string,
`product/queuetype` string,
`product/readtype` string,
`product/realtimeoperation` string,
`product/recipient` string,
`product/region` string,
`product/requestdescription` string,
`product/requesttype` string,
`product/resolution` string,
`product/resourceendpoint` string,
`product/resourcetype` string,
`product/rootvolume` string,
`product/routingtarget` string,
`product/routingtype` string,
`product/runningmode` string,
`product/servicecode` string,
`product/servicename` string,
`product/singleordualpass` string,
`product/sku` string,
`product/softwareincluded` string,
`product/softwaretype` string,
`product/standardstorageretentionincluded` string,
`product/steps` string,
`product/storage` string,
`product/storageclass` string,
`product/storagedescription` string,
`product/storagemedia` string,
`product/storagetype` string,
`product/subscriptiontype` string,
`product/supportedmodes` string,
`product/tenancy` string,
`product/tenancysupport` string,
`product/throughput` string,
`product/throughputclass` string,
`product/tier` string,
`product/tiertype` string,
`product/tolocation` string,
`product/tolocationtype` string,
`product/trafficdirection` string,
`product/transcodingresult` string,
`product/transfertype` string,
`product/type` string,
`product/updates` string,
`product/usagefamily` string,
`product/usagetype` string,
`product/uservolume` string,
`product/vcpu` string,
`product/version` string,
`product/videocodec` string,
`product/videoframerate` string,
`product/videomemorygib` string,
`product/videoquality` string,
`product/videoqualitysetting` string,
`product/videoresolution` string,
`product/virtualinterfacetype` string,
`product/volumeapiname` string,
`product/volumetype` string,
`product/vqsetting` string,
`pricing/leasecontractlength` string,
`pricing/offeringclass` string,
`pricing/purchaseoption` string,
`pricing/publicondemandcost` double,
`pricing/publicondemandrate` double,
`pricing/term` string,
`pricing/unit` string,
`reservation/amortizedupfrontcostforusage` string,
`reservation/amortizedupfrontfeeforbillingperiod` double,
`reservation/availabilityzone` string,
`reservation/effectivecost` string,
`reservation/endtime` string,
`reservation/modificationstatus` string,
`reservation/normalizedunitsperreservation` double,
`reservation/numberofreservations` bigint,
`reservation/recurringfeeforusage` string,
`reservation/reservationarn` string,
`reservation/starttime` string,
`reservation/totalreservednormalizedunits` double,
`reservation/totalreservedunits` double,
`reservation/unitsperreservation` double,
`reservation/unusedamortizedupfrontfeeforbillingperiod` double,
`reservation/unusednormalizedunitquantity` double,
`reservation/unusedquantity` double,
`reservation/unusedrecurringfee` double,
`reservation/upfrontvalue` double,
`resourcetags/user:cmbillinggroup` string,
`savingsplan/totalcommitmenttodate` double,
`savingsplan/savingsplanarn` string,
`savingsplan/savingsplanrate` string,
`savingsplan/usedcommitment` string,
`savingsplan/savingsplaneffectivecost` string,
`savingsplan/amortizedupfrontcommitmentforbillingperiod` string,
`savingsplan/recurringcommitmentforbillingperiod` double,
`savingsplan/region` string,
`savingsplan/paymentoption` string,
`savingsplan/endtime` string,
`savingsplan/instancetypefamily` string,
`savingsplan/purchaseterm` string,
`savingsplan/offeringtype` string,
`savingsplan/starttime` string
)
PARTITIONED BY (
`account_id` string,
`export_name` string,
`date` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://cm-cur-aggregate-123456789012/mcur/'
TBLPROPERTIES (
'partition_filtering.enabled'='true',
'projection.enabled'='true',
'projection.account_id.type'='enum',
'projection.account_id.values'='123456789012',
'projection.export_name.type'='enum',
'projection.export_name.values'='account-cur-csv',
'projection.date.type'='date',
'projection.date.range'='202412,NOW+9HOURS',
'projection.date.format'='yyyyMM',
'projection.date.interval'='1',
'projection.date.interval.unit'='MONTHS',
'classification'='csv',
'compressionType'='gzip',
'storage.location.template'='s3://cm-cur-aggregate-123456789012/mcur/account_id=${account_id}/export_name=${export_name}/date=${date}'
);
TBLPROPERTIES 部分でPartition Projectionの設定を行なっています。
これで必要なカラムとパーティションが作成され、Athenaで分析可能になります。
2つの方法の比較
Glueを使った方法と、AthenaのPartition Projectionを使った方法のメリット/デメリットについてまとめます。
ご自身の環境により使い分けてください。
| Glueを使った方法 | AthenaのPartition Projectionを使った方法 | |
|---|---|---|
| 環境構築 | 複雑 | 単純 |
| クエリのパフォーマンス *1 | 高 | 低(くなる可能性がある) |
| 汎用性 *2 | 高 | 低 |
*1:
Partition Projectionでは、クエリ実行時のWHERE句でパーティションを指定せずにフルスキャンした場合、設定した全てのパーティションを読みにいってパフォーマンスが低下する可能性があります。
projection.date.range の指定には注意してください。
下記エントリが参考になります。
*2:
Partition ProjectionはAthenaのクエリエンジンのみサポートする機能なので、別のクエリエンジンではデータが参照できません。Redshift Spectrum、Glue、EMRなど、別のサービスを通じて同じテーブルを参照する場合はパーティションが登録されていないため利用できません。
Athenaでの分析
これまでの設定で、CURをAthenaで分析可能になります。
CURの各カラムについては、AWSのドキュメントをご確認ください。
クエリサンプル
Athenaの環境構築が完了したことを確認するため、クエリを実行してみます。
例として、メンバーズポータルで表示される料金を確認します。
WITH "categorized" AS (
SELECT
"date",
"lineitem/usageaccountid",
CASE
WHEN "lineitem/lineitemtype" = 'Fee' THEN '前払料金'
WHEN "lineitem/lineitemtype" IN ('RIFee', 'SavingsPlanRecurringFee') THEN '毎月料金'
WHEN "bill/billingentity" = 'AWS Marketplace' THEN 'マーケットプレイス料金'
WHEN "bill/billingentity" = 'CM' AND "product/productname" = 'Classmethod Members Discount' THEN 'メンバーズ割引'
ELSE '通常利用料金'
END AS "category",
CAST("lineitem/unblendedcost" AS DECIMAL(24, 10)) AS "lineitem/unblendedcost"
FROM "members-cur"."mcur"
)
SELECT
"date",
"lineitem/usageaccountid",
"category",
SUM("lineitem/unblendedcost") AS "lineitem/unblendedcost"
FROM "categorized"
WHERE "date" = '202412' -- 分析したい年月
AND "lineitem/usageaccountid" IN (
'123456789012' -- 分析したいアカウントのID
)
GROUP BY
"date",
"lineitem/usageaccountid",
"category"
ORDER BY
"date",
"lineitem/usageaccountid",
"category"
まとめ
メンバーズのCURをAthenaを使って分析する環境構築方法について説明しました。
ぜひ詳細な分析に役立ててください!









